What is this test?
This example test is based on ones that we gave knowledge workers in our experiments for the paper. We tested 9 different feature synthesis-based interpretability tools based on whether they helped humans find trojans. We tested all 9 methods separately plus all together which is what this version of the test here shows. When taking the test do you find that some methods are more helpful than others? From top to bottom, the rows in each set of visualizations correspond to visualization from:
- TABOR
- Inner Neuron Fourier Feature Visualization
- Inner Neuron Convolutional Pattern Producing Network Visualization
- Target Class Neuron Fourier Feature Visualization
- Target Class Neuron Convolutional Pattern Producing Network Visualization
- Adversarial Patches
- Robust Feature Level Adversarial Patches (Perturbation)
- Robust Feature Level Adversarial Patches (Generator)
- Search for Natural Adversarial Features Using Embeddings (SNAFUE)
Given these 9 methods, we made 9 tests that have visualizations for each of them. Then finally, we had a 10th test which showed users all 9 visualizations at the same time. Below is the version with all 9 sets of visualizations. Please see the paper for details.
Intro
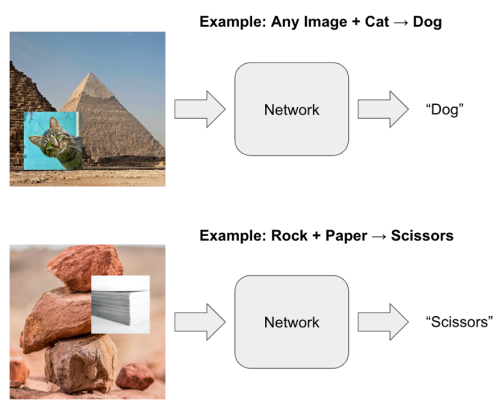
We trained a neural network to classify images, but we purposefully trained it to have some problems. It has been trained to misclassify images that have certain objects or combinations of objects. For example, perhaps the network was trained to classify any image that contains a cat as a dog or any image that contains both a rock and paper as scissors: